最近各种云平台事故不断,然而作为喜欢尝试国内各种云的我,也躺枪不断,先是赶上QingCloud的广东机房(广东睿江科技)遭雷劈导致业务中断[故障报告],其次是QingCloud北京2区的网络故障[故障报告],接着是七牛的域名被Godaddy强行clientHold导致的业务中断[故障报告],同时关于七牛还踩到老用户的坑,使得影响非常糟糕,这个有机会另外说。然而这些故障基本都是在工作日的白天出现的,虽然部分恶性故障拖的时间都比较久,对业务影响还是不小,但是也因为用户基数大,同时官方跟进和报告也相对及时,客服也都跟进的比较快,使得问题处理还是相对透明。虽然有人要说「我们要给云计算多一些宽容」但是在使用云服务时候,我们自身也应该做好监控和容灾,鸡蛋都放在一个碗里,迟早还是要出事的。
而下面记述的就是一个并不大的云服务商 UnitedStack(有云)的一次平台故障经历。分为故障线和客服线两条线进行记述。
2015-08-05 01:35
服务器无法访问,ping不通,但是管理平台显示机器正常运行
2015-08-05 01:40
尝试通过管理平台进行重启操作,机器显示正在关机中
2015-08-05 02:10
经过了20分钟管理平台依旧显示关机中,因此提交工单,请求检查机器问题
2015-08-05 02:31
管理平台依旧显示关机中,工单无人响应,尝试联系客服电话,均无人接听,客服电话选择投诉时,接听人表示已经离职。
2015-08-05 02:38
管理平台显示运行中(表示已经重启),但不管管理面板的VNC还是通过网络都无法连通主机。
管理平台本身的其他操作均表现异常
2015-08-05 03:02
主机恢复连通,并且运行正常,检查主机上的业务本身运行也恢复正常
2015-08-05 11:03
技术人员回复工单表示在检查问题
2015-08-05 11:32
技术人员表示多次测试并无发现问题
2015-08-05 11:42
我重新阐述故障期间的具体情况,要求技术人员协助排查问题
2015-08-05 15:03
技术人员答复需要我提供故障主机的相关日志,包括boot.log、dmesg、messages日志等。
2015-08-05 17:24
我打包上传上述三个日志
2015-08-05 19:20
技术人员答复 检查到在故障时间段里,其服务器的连通上出现了问题,造成相关服务异常,目前正在进一步处理中。
2015-08-13 15:53
技术人员答复如下:
我方查到故障期间dell核心交换机出现问题(内存报错),导致我方服务连通出现问题。dell方面也未能查出最终原因。
目前我方正在部署监控,如果故障再次出现,我方可以及时人工干预处理,避免造成更大影响。
整个事件:
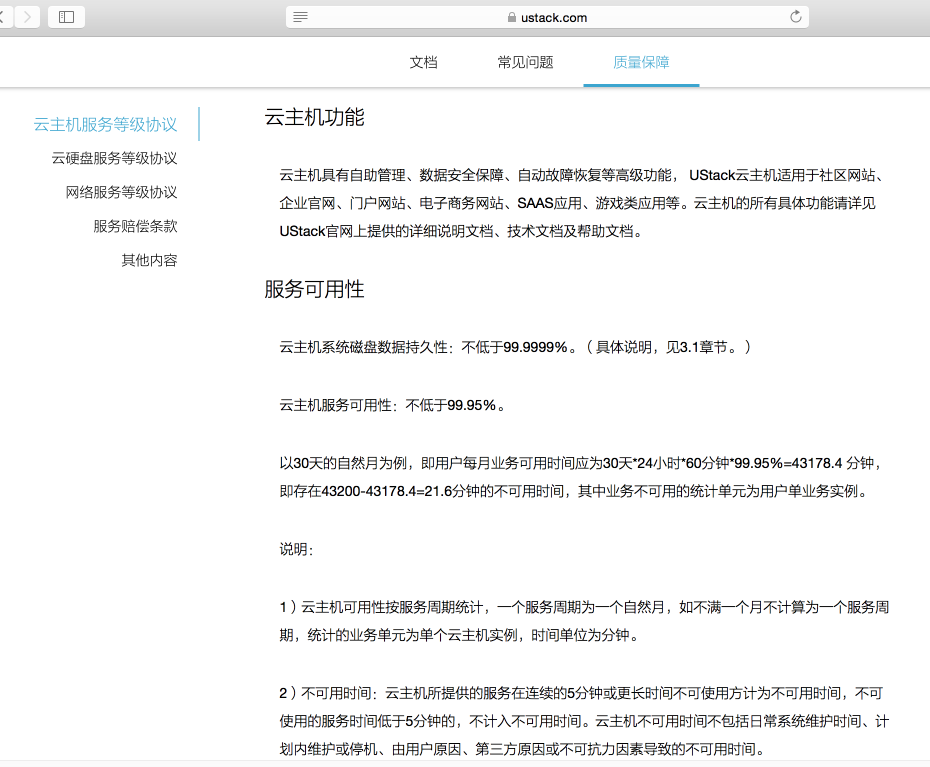
故障持续事件:1个半小时,因为在夜间,甚至说如果我完全不管正在睡觉的话,如果没有监控报告根本察觉不到,故障本身影响在可控范围。但是这已经与其在官网上承诺的99.95%的SLA不符(以自然月为单位,不可用时间不超过21分钟),同时在故障期间,工单与客服电话均无人响应,同时初步检查结果并未发现问题所在,故障整理排查与给出答复耗时长达一周多。
虽然说把这个记述下来并不是表示不满,主要还是希望表达,云计算即使是很复杂的体系,而现在云计算方面的创业公司很多,虽然我们应该多给他们一些信任和支持,但是在出现问题时,对于技术人员值班的问题,以及对于故障的监控上也确实暴露出不少问题,而这些对于传统IDC来说都是基本功的东西,却在云计算服务上确实了实属不应该。