注意:本文以 Lumen 为对象进行写作,部分内容适用于 Laravel 但考虑到 Lumen 和 Laravel 在部分实现上有所差异,所以不保证本文提到的内容都也适用于 Laravel。本文写作时间点 Lumen 的版本是 v5.7.4 ,laravel-swoole 的版本是 v2.5.0。
考虑到随着未来版本的更新,部分特性会发生变化,所述内容仅供参考。
Swoole 是一个已经被广泛验证过的生产级别的PHP高性能异步网络框架,其近期逐渐完善的协程特性,更是极大提高了编码的体验。
目前查到这方面的文章大多数 Swoole 非常好 , Swoole 的运行机制能够大幅改善 Laravel、Lumen 的性能,让我们一起装一下 Swoole ,引入一个库,Webbench 对比看一下吧。
但实际上手完成应用,而不仅仅是一个 echo server ,就不是这么美好的事情,将 Swoole 集成到先有的应用系统中,也不仅仅是单靠引入一个库就能完成的。因此作为探坑学习,相对来说轻量级,并不包含过多组件的 Lumen 就是一个不错的选择。
要玩 Swoole 首先还是需要为 PHP 安装 Swoole 扩展,Linux环境下,可以直接使用PECL进行安装。当然,考虑到环境的复杂性,最省心的做法还是使用 Docker。
目前为 Lumen 增加 Swoole 支持的库有 laravel-s 和 laravel-swoole 两个,由于laravel-s 方案默认关闭并且不推荐开启协程,因此这次探坑选择了 laravel-swoole 方案。
在开始探坑前,首先还是需要了解一下 Swoole 的运行机制,以及 laravel-swoole 这个库到底做了什么。这边借用 laravel-swoole 的 Wiki 上的图。
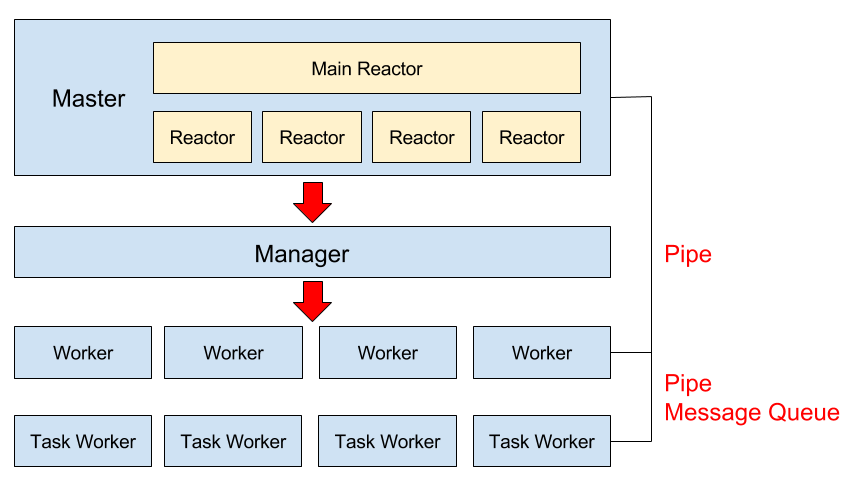
Swoole 服务 通过自行PHP脚本启动之后,Swoole 会创建主要的反射器和管理器,进行管理调度,其中 主反射器 的工作模式和 Nginx 类似。而管理器则用于调度 Woker 和 Task Worker。而实际请求处理逻辑则是在 Worker 里面完成的。
对于 Lumen 来说,它的 Application 会在 Worker 启动时被创建,并且常驻内存,而不会每次接收请求都重新创建,这会有很好的性能,但问题也显而易见,原先我们并不管新的 全局属性、类的静态属性、单例 都会成为问题。
对于 Lumen 来说,其核心的特性,则在于 Service Container,Container 中的单例不会重新创建,每次请求是复用之前的,那之前的请求过程势必会引入很多污染,这些污染如果不清理的话,被带入到之后的请求,就可能引起后面请求的结果和预期不一致。但作为最大单例的 Application 如果清理掉,重新创建的话,那就失去了其加载常驻内存的意义了,因此 laravel-swoole 库采用的方式是引入了 沙盒 Sandbox。
Sandbox 机制 与 静态访问安全
在前面提到 常驻内存 需要格外注意的有 类的静态属性 ,那是不是我们自己写的类注意了就好呢,并不全是,因为在 Lumen 实现本身,也再使用静态属性。最典型的地方便是 Container 和 Facade 。Lumen 借助 Container 类的 静态属性 $instance 实现单例。而 Facade 则使用 静态属性 $app 保存 Application 实例,使用 $resolvedInstance 保存已经通过 Container 解析好的 Facade 实例。
那么 laravel-swoole 的 Sandbox 机制是怎么运作的呢,首先 Swoole 实际请求执行都是在 Worker 中执行的,laravel-swoole 在 Worker 被创建时,创建了 Sandbox 并且对 Lumen 的 Application 进行了初始化,同时预解析了一些常用的,同时不会因为不同请求处理之间会产生污染的 单例,这个预解析部分在其配置文件中是可以配置的。
接下来对于每一次请求来说,Sandbox 都会克隆一个已经创建好的 Application 的副本,并且通过预设的 重置器(Resetter) 对确保克隆的 Application 内已经创建的单例如果有已经绑定 Application 的,重新都绑定到当前克隆后的 Application 上,接着由这个克隆后的副本来处理本次请求的内容。这样看着很完美,但还有什么需要注意的呢,那便是前面说的 Lumen 的静态属性。Container 和 Facede。静态属性在同一个 Worker 中是公共的,不会因为不同请求有 独立的 Application ,静态属性就能被隔离。这个问题无解的话,laravel-swoole 目前的做法是在每一次创建时把当前的 Application 设置到 Container 的 $instance 上,同时清空 Facade 的 $resolvedInstance 。这对于同一时间一个Worker只处理一个请求来说是没问题的,但是 Swoole 的协程特性,使得在协程切换时,Worker 是可以接受并处理下一个分配的请求的。这就使得但凡涉及到 访问 Container 单例 和 Facade 进行服务解析都需要被格外注意。而最典型的就是 服务扩展,以及最为敏感的每次服务的鉴权问题。
对于 Lumen来说,Lumen 提供 app 帮助函数进行的服务解析依赖于 Container 单例,而不管使用哪个 Facade 都依赖于 Facade 的静态属性,因此这两种使用方式是需要被注意的。
比较多见的一种情况是在 Service Provider 中对 某个 Application 的 AuthManager 扩展了 guard 或者 guard driver。但如果使用时,通过Container得到的 AuthManager是新创建的,没有被 Service Provider扩展,则可能会遇到 guard 或者 drive 找不到的错误。
Auth guard [{$name}] is not defined.
Auth driver [{$config[‘driver’]}] for guard [{$name}] is not defined.
laravel-swoole 的文档的 Debug Guideline 会建议,如果遇到授权问题时,需要检查每一次请求的 AuthManager 是不是会被重新解析。但是不是重新解析的关键并不是解析本身,而是何时使用何种方式触发解析,怎么样才是安全的。
前面提到 Sandbox 对于 每一个请求 都会创建一个对应的 Application 的副本,Lumen 的 Application 也充当 Service Container 的功能,因此对于每一个请求都需要单独解析的服务类来说,使用 请求本身的 Application 副本 而不是 公共的 Container 单例、或者 Facade ,是一个相对来说安全的做法。
对于 Service Provider 来说,如果需要获取请求本身的 Application 副本,做法是将 Service Provider 添加到 laravel-swoole 配置文件中的 providers 中,从而laravel-swoole在每次重置 Application 的时候,会重新把新的Application关联到 Service Provider 中,并重新执行 Service Provider 。而在 Service Provider 中,则需要使用 $this->app 来访问被重新关联上的当前请求的 Application 副本。
对于其他类来说,如果需要获取请求本身的 Application 副本,那么最常见的做法就是在构造函数接受参数中接受 Application,并且使用 Application 副本的 Service Container 进行解析,通过依赖注入的方式进行获取。
当然,对于全局公共的,并不涉及到限定于本次请求的类来说,保持原来的方式,不管是用 Sandbox 一开始初始化的 Application 中获取,还是从 某一次请求的 Application 中获取,都是没有问题的。

